| Exam Name: | Google Professional Machine Learning Engineer | ||
| Exam Code: | Professional-Machine-Learning-Engineer Dumps | ||
| Vendor: | Certification: | Machine Learning Engineer | |
| Questions: | 285 Q&A's | Shared By: | alexia |
You need to quickly build and train a model to predict the sentiment of customer reviews with custom categories without writing code. You do not have enough data to train a model from scratch. The resulting model should have high predictive performance. Which service should you use?
You are designing an architecture with a serverless ML system to enrich customer support tickets with informative metadata before they are routed to a support agent. You need a set of models to predict ticket priority, predict ticket resolution time, and perform sentiment analysis to help agents make strategic decisions when they process support requests. Tickets are not expected to have any domain-specific terms or jargon.
The proposed architecture has the following flow:
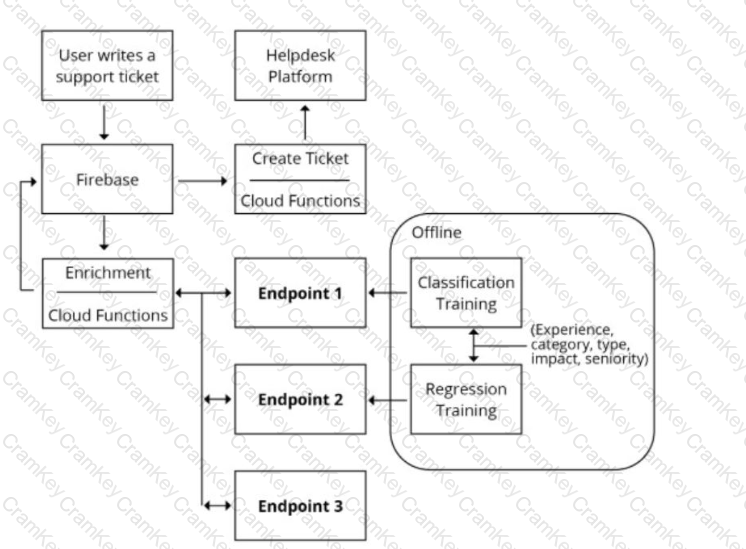
Which endpoints should the Enrichment Cloud Functions call?
You are using Kubeflow Pipelines to develop an end-to-end PyTorch-based MLOps pipeline. The pipeline reads data from BigQuery,
processes the data, conducts feature engineering, model training, model evaluation, and deploys the model as a binary file to Cloud Storage. You are
writing code for several different versions of the feature engineering and model training steps, and running each new version in Vertex Al Pipelines.
Each pipeline run is taking over an hour to complete. You want to speed up the pipeline execution to reduce your development time, and you want to
avoid additional costs. What should you do?
As the lead ML Engineer for your company, you are responsible for building ML models to digitize scanned customer forms. You have developed a TensorFlow model that converts the scanned images into text and stores them in Cloud Storage. You need to use your ML model on the aggregated data collected at the end of each day with minimal manual intervention. What should you do?

TESTED 26 Apr 2025