| Exam Name: | Databricks Certified Data Engineer Professional Exam | ||
| Exam Code: | Databricks-Certified-Professional-Data-Engineer Dumps | ||
| Vendor: | Databricks | Certification: | Databricks Certification |
| Questions: | 202 Q&A's | Shared By: | myra |
The data engineer team has been tasked with configured connections to an external database that does not have a supported native connector with Databricks. The external database already has data security configured by group membership. These groups map directly to user group already created in Databricks that represent various teams within the company.
A new login credential has been created for each group in the external database. The Databricks Utilities Secrets module will be used to make these credentials available to Databricks users.
Assuming that all the credentials are configured correctly on the external database and group membership is properly configured on Databricks, which statement describes how teams can be granted the minimum necessary access to using these credentials?
A table named user_ltv is being used to create a view that will be used by data analysis on various teams. Users in the workspace are configured into groups, which are used for setting up data access using ACLs.
The user_ltv table has the following schema:

An analyze who is not a member of the auditing group executing the following query:
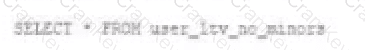
Which result will be returned by this query?
A data engineer is attempting to execute the following PySpark code:
df = spark.read.table( " sales " )
result = df.groupBy( " region " ).agg(sum( " revenue " ))
However, upon inspecting the execution plan and profiling the Spark job, they observe excessive data shuffling during the aggregation phase.
Which technique should be applied to reduce shuffling during the groupBy aggregation operation?
A data architect has designed a system in which two Structured Streaming jobs will concurrently write to a single bronze Delta table. Each job is subscribing to a different topic from an Apache Kafka source, but they will write data with the same schema. To keep the directory structure simple, a data engineer has decided to nest a checkpoint directory to be shared by both streams.
The proposed directory structure is displayed below:

Which statement describes whether this checkpoint directory structure is valid for the given scenario and why?

TESTED 26 Jul 2026