| Exam Name: | Databricks Certified Data Engineer Professional Exam | ||
| Exam Code: | Databricks-Certified-Professional-Data-Engineer Dumps | ||
| Vendor: | Databricks | Certification: | Databricks Certification |
| Questions: | 202 Q&A's | Shared By: | sam |
Review the following error traceback:

Which statement describes the error being raised?
The data engineering team has configured a Databricks SQL query and alert to monitor the values in a Delta Lake table. The recent_sensor_recordings table contains an identifying sensor_id alongside the timestamp and temperature for the most recent 5 minutes of recordings.
The below query is used to create the alert:
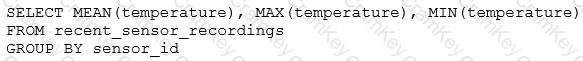
The query is set to refresh each minute and always completes in less than 10 seconds. The alert is set to trigger when mean (temperature) > 120 . Notifications are triggered to be sent at most every 1 minute.
If this alert raises notifications for 3 consecutive minutes and then stops, which statement must be true?
A data team ' s Structured Streaming job is configured to calculate running aggregates for item sales to update a downstream marketing dashboard. The marketing team has introduced a new field to track the number of times this promotion code is used for each item. A junior data engineer suggests updating the existing query as follows: Note that proposed changes are in bold.

Which step must also be completed to put the proposed query into production?
A data engineer is implementing Unity Catalog governance for a multi-team environment. Data scientists need interactive clusters for basic data exploration tasks, while automated ETL jobs require dedicated processing.
How should the data engineer configure cluster isolation policies to enforce least privilege and ensure Unity Catalog compliance?

TESTED 29 Jul 2026