Databricks Certified Machine Learning Associate Exam
Last Update Aug 2, 2026
Total Questions : 74
To help you prepare for the Databricks-Machine-Learning-Associate Databricks exam, we are offering free Databricks-Machine-Learning-Associate Databricks exam questions. All you need to do is sign up, provide your details, and prepare with the free Databricks-Machine-Learning-Associate practice questions. Once you have done that, you will have access to the entire pool of Databricks Certified Machine Learning Associate Exam Databricks-Machine-Learning-Associate test questions which will help you better prepare for the exam. Additionally, you can also find a range of Databricks Certified Machine Learning Associate Exam resources online to help you better understand the topics covered on the exam, such as Databricks Certified Machine Learning Associate Exam Databricks-Machine-Learning-Associate video tutorials, blogs, study guides, and more. Additionally, you can also practice with realistic Databricks Databricks-Machine-Learning-Associate exam simulations and get feedback on your progress. Finally, you can also share your progress with friends and family and get encouragement and support from them.
A data scientist is utilizing MLflow Autologging to automatically track their machine learning experiments. After completing a series of runs for the experiment experiment_id, the data scientist wants to identify the run_id of the run with the best root-mean-square error (RMSE).
Which of the following lines of code can be used to identify the run_id of the run with the best RMSE in experiment_id?
A)

B)

C)
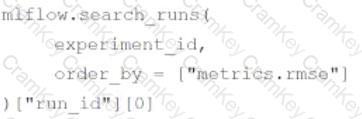
D)

A data scientist is using the following code block to tune hyperparameters for a machine learning model:

Which change can they make the above code block to improve the likelihood of a more accurate model?
A data scientist learned during their training to always use 5-fold cross-validation in their model development workflow. A colleague suggests that there are cases where a train-validation split could be preferred over k-fold cross-validation when k > 2.
Which of the following describes a potential benefit of using a train-validation split over k-fold cross-validation in this scenario?
A data scientist has created a linear regression model that useslog(price)as a label variable. Using this model, they have performed inference and the predictions and actual label values are in Spark DataFramepreds_df.
They are using the following code block to evaluate the model:
regression_evaluator.setMetricName("rmse").evaluate(preds_df)
Which of the following changes should the data scientist make to evaluate the RMSE in a way that is comparable withprice?

TESTED 02 Aug 2026